
Google検索エンジンとランキングシステムの仕組み |2023年12月16日
Googleは、完全に自動化された検索エンジンです。
GoogleがどのようにWEBサイトをインデックスし、評価して順位付けを行うのか、サイト運営者は知っておくべき事項です。
特に検索順位の決定方法はSEOの観点からも興味があるでしょう。
Googleの検索エンジンの仕組みについては、下記のページにて解説されています。
Google の検索エンジンの仕組み、検索結果と掲載順位について
Google検索の3つのステージの流れ
Google検索には、次の3つのステージがあります。
クロール:
Googleは、クローラーと呼ばれる自動プログラムを使用して、ウェブ上で見つけたページからテキスト、画像、動画をダウンロードします。
インデックス登録:
Googleは、見つけたページ上のテキスト、画像、動画ファイルを解析し、その情報を Googleインデックス(大規模なデータベース)に保存します。
検索結果の表示:
ユーザーが Google で検索すると、Google はユーザーの検索語句に関連する情報を返します。
Googlebotによるクロールとは
Googlebotとは、大規模なコンピュータ群を使用して、WEB上の数十億のページをクロール、つまりページを取得し読み込んで、さらにリンクをたどって別のページも取得して読み込むことを、自動的に繰り返し行うプログラムです。
この取得プログラムはGooglebotと呼ばれており、Bingなどの他の検索エンジンでも同様の動作を行う児童プログラム(ロボット)があります。
クローラー、ロボット、ボット、スパイダーなどと呼ばれることもあります。
Googlebotは新しいページや更新されたページを絶えず検出し、既知のページリストに加えます。
未知のページの検出をURL検出といい、リンクをたどって発見するほか、GoogleSearchConsoleの画面から、WEBサイト管理者がクロールのリクエストをすることもできます。
サイトに設置したサイトマップのXMLファイルからGooglebotがリンクをたどることもあるでしょう。
SEOのヒント
新しいページは、既知のページやサイトマップのXMLファイルから、リンクをたどることで検出されます。
トップページや各ページに設置されたナビゲーションや、カテゴリページなどのハブページにあるリンク、パンくずリストや記事中の内部リンクなどです。
サイトマップは、XMLファイルと、閲覧者にも便利なHTMLのページとを用意しておくのがよいでしょう。
外部サイトからのリンクをたどってクローラーが訪問することもあります。
GooglebotがページのURLを検出すると、そのページにアクセスして内容を確認します。
Googlebotはクロール中、アクセスしたユーザーのブラウザと同じ挙動で、Chrome最新版を使用してページをレンダリングします。
かつては難しかったJavaScriptも実行してレンダリングすることができます。
Googleがすでにアクセスしたことのあるページは、既知のページとなります。
Googlebotは、クロールするサイト、クロール頻度、各サイトから取得するページ数をアルゴリズムにより決定します。
クロールの対象になるかどうかは、Googleのクローラーがサイトにアクセスできるかどうかのほか次の要因により決定されます。
- サーバーによるサイトの処理に関する問題
- ネットワークに関する問題
- Googlebotによるページへのアクセスを制御するrobots.txt
SEOのヒント
クロール頻度は、以前はSearchConsoleでの設定項目がありましたが、sitemap.xmlに更新頻度を記載するなどしてgoogleに伝えることができます。
Googlebotは検出したページをすべてクロールするわけではなく、サイトやネットワークに問題がある場合や、スパム扱いされているサイト、クロールが禁止されているページやログインが必要なページなどはクロールから除外されるかもしれません。
保護したいページはrobots.txtやベーシック認証などで適切に設定する必要があります。
インデックス登録
クローラーが収集したページと、そのグループについて収集された情報は、Googleインデックスに保存されます。
これをインデックスする、あるいはインデックス登録といいます。
インデックス登録されるGoogleデータベース
Googleインデックスは、何千台ものコンピュータでホストされている大規模な分散型データベースです。
一か所のデータベースに保存されているイメージではなく、検索するごとに順位が微妙に変わることがあるのも、検索結果を取得するデータベースが異なることがあるからかもしれません。
インデックス登録されない場合
インデックス登録されるかは、保証されているわけではなく、Googleが処理するページのすべてがインデックスに登録されるとは限りません。
次のような場合にインデックス登録がされないことがあります。
- 重複コンテンツであり、正規ページではない
- ページのコンテンツの品質が低い
- robots meta ルールによってインデックス登録が禁止されている
- ウェブサイトのデザインが原因でインデックス登録が困難になっている
正規ページの判定
インデックス登録を行う際、GoogleはページがWEB上の別のページの重複ページであるか、または正規ページであるかを判断します。
正規ページは、検索結果に表示される可能性のあるページです。
Googleが正規ページを判断するプロセスは、次の通りです。
インターネット上で見つけた同じようなコンテンツを含むページをグループ化(クラスタリング)し、グループを代表するページを正規のページとして選択します。
選択されなかった他のページは、ユーザーがモバイル検索をしたときや、特定のページを探している場合などに、表示される可能性のある代替バージョンと判断されます。
インデックス登録される情報
各ページの内容や付随する情報は、インデックス登録される際にGoogleが把握して保存します。
インデックスにウェブページが登録されると、そのページに含まれるすべての語がインデックスに追加されます。(Google 検索における情報の整理方法)
インデックス登録では、title要素やh1, h2, h3などの見出し要素、alt属性など、テキストコンテンツや主要なコンテンツのHTMLタグや属性、そして画像や動画などを処理して分析する作業までを行います。
また、Googleはページとコンテンツに関するシグナル、たとえばページの言語、コンテンツの配信元の国、ページの使いやすさなどの情報も保存します。
構造化データ、ページ同士のリンク、その他の各種データもインデックスに登録され、登録されたデータは検索結果を表示する際に役立てられます。
Googleのランキングアルゴリズムは、詳細は公開されていません。
1,000以上のランキング要因があり、日々ランキング要素は更新されます。
検索結果への表示
Google検索のランキングは、プログラムによって決定されます。
検索インデックスに登録されている膨大な数のウェブページとその他のコンテンツを分類し、最も関連性の高い有用な結果を瞬時に提示します。
ランキングプログラムの仕組み
もっとも有用な情報を表示するため、検索アルゴリズムはさまざまな要因とシグナルにと同期ランキングを決定します。
ランキング要因となるシグナルには、検索クエリの単語、ページの関連性や有用性、ソースの専門性、ユーザーの位置情報や設定などがあります。
各要因に適用される重み付けはクエリの性質によって異なります。
結果を自動的に生成する仕組み
ランキングは、検索クエリごとに決定されます。
検索クエリの意味
関連性の高い結果を返すには、ユーザーがどんな情報を探しているか、つまり検索クエリの背後にどんな意図があるかをまず理解する必要があります。
Googleでは、検索ボックスに入力された比較的少数の単語と、もっとも有益なコンテンツとのマッチングの程度を把握するための言語モデルを構築しています。
SEOのヒント
Googleが検索クエリをどのように解釈しているかは、実際に検索を行い、上位表示されているWEBページのタイトルや見出し、内容を確認していくことで類推することができます。
再検索キーワード、サジェストキーワードもクエリのユーザー意図を推認することに役立ちます。
コンテンツの関連性
ランキングシステムはコンテンツを分析して、ユーザー意図に関連する可能性のある情報が含まれているかを評価します。
情報の関連性を評価するためのもっとも基本的なシグナルは、検索クエリと同じキーワードがコンテンツに含まれているかどうかです。
WEBページのに出現するキーワード、特に見出しや本文にクエリが含まれている場合には、そのページの情報は関連性が高い可能性があります。
SEOのヒント
タイトルや見出しにキーワードを含めることは重要ですが、一方で不自然な見出しや、過度なキーワードの羅列、詰め込みはマイナス要因となることがあります。
コンテンツの質
ランキングシステムは、関連性のあるコンテンツを特定し、もっとも役立ちそうなコンテンツを優先しようとします。
そのために、どのコンテンツが専門性、権威性、信頼性を示しているか判定するために役立つシグナルを特定します。
判定を支援するために使用している要因の1つに、そのコンテンツへのリンクまたは言及が、他の著名なウェブサイトに含まれているか把握することがあります。
含まれていれば、多くの場合にはその情報の信頼性が高いことを示す十分なシグナルとなります。
SEOのヒント
経験、専門性、権威性、信頼性(E-E-A-T)については、Googleの検索結果を評価する検索品質評価者のためのガイドラインに詳細な解説があります。
Googleでは、検索品質評価プロセスからのフィードバックを集計し、より正確に情報の質を判定できるようシステムを改善しています。
ウェブサイトのユーザビリティ
Googlenのランキングシステムでは、コンテンツのユーザビリティも考慮されます。
どのコンテンツも大きな差がない場合には、ユーザーエクスペリエンスの観点からランキングが決定される可能性があります。
コンテキストと設定
現在地、過去の検索履歴、検索設定などの情報はすべて、検索の時点でもっとも有用で関連性が高い検索結果を確保するために役立っています。
ユーザーが行う検索の設定も重要です。
検索の設定では、使用する言語の指定、セーフサーチの有効化などができます。
ユーザーが入力したクエリとの関連性は、ユーザーの所在地、言語、デバイス(パソコンまたはスマートフォン)などの情報を含め、数多くの要素によって決まります。
SEOのヒント
検索履歴などの影響を除外した検索結果を確認するには、Chromeのシークレットモードや、他のブラウザの同様の機能を使用した状態で検索する方法があります。
Google検索のランキングシステム
Googleのさまざまなランキングシステム
Googleは、多種多様な要素やシグナルを検討する自動ランキング \システムを使用して、検索インデックスにある数千億のウェブページやその他のコンテンツから、最も関連性の高い、有益な結果が一瞬で表示されるようにしています。
Google検索ランキングシステムのご紹介
これらのシステムは厳格なテストと評価により定期的に改善され、重要な変更の際にはランキングシステムのアップデートの通知が行われています。
以下は、検索クエリに対して検索結果を生成する基盤テクノロジーである、Googleコアランキングシステムの代表的なアルゴリズムです。
BERT
BERT(Bidirectional Encoder Representations from Transformers)は、Google が使用するAIシステムです。
単語の組み合わせによって、多様な意味や意図がどのように表現されるかを理解できるようにするものです。
災害情報システム
個人の危機的状況、自然災害、その他の広範囲に及ぶ危機的状況など、あらゆる危機発生時に有用でタイムリーな情報を提供するためのシステムです。
Googleのシステムは、自殺、犯罪などに関連する検索クエリが入力されると、ユーザーが個人の危機にかかわる情報を探していると判断し、ホットラインや信頼できる組織が提供するコンテンツを表示する仕組みになっています。
自然災害時や広範囲に影響が及ぶ危機的状況下では、SOS 緊急情報システムにより地方自治体、国家機関、国際機関からの最新情報が表示されます。この情報には、緊急電話番号やウェブサイト、地図、役に立つフレーズの翻訳、寄付の方法などがあります。
重複除去システム
Googleで検索すると、数千、時には数百万の一致するウェブページが見つかることがあり、その中には、互いに非常に似通ったものがある可能性もあります。
そのような場合には、もっとも関連性の高い結果のみが表示され、有益性の低い重複内容は除去されます。
SEOのヒント
検索結果の最後まで到達したとき、一部の検索結果は除外された旨のメッセージが表示され、ここで「検索結果をすべて表示する」をクリックすると、除外されたページも含めた検索結果が確認できます。
重複除去は強調スニペットでも発生し、強調スニペットに表示されたページがそれ以降の検索結果に出ることはありません。
完全一致ドメイン システム
Googleのランキングシステムでは、ドメイン名に含まれる単語を、コンテンツが検索に関連しているかどうかを判断するための多くの要素の一つとみなしています。
ただし、ドメイン名が特定の検索クエリと完全一致することを意図して付けられている場合に、そのドメインのコンテンツを過度に評価しないこととされています。
フレッシュネス システム
より鮮度の高いコンテンツが期待されると判断された検索クエリについて、そのようなコンテンツが上位に表示されるように、「検索クエリにふさわしい鮮度」を評価するさまざまなシステムを導入しています。
ヘルプフルコンテンツシステム
ヘルプフルコンテンツシステムは、検索エンジンのトラフィックを集めることを主な目的として作成されたコンテンツではなく、人間が人間のために作成した、独自性の高い有益なコンテンツが検索結果で表示されるようにするためのシステムです。
SEOのヒント
Google検索のヘルプフルコンテンツシステムとウェブサイトでは、次のように説明されています。
「価値や付加価値が低い、あるいはユーザーにとって特に有用ではないと思われるコンテンツが自動的に識別されます。
有用ではないコンテンツ自体だけでなく、そうしたコンテンツを比較的多く含むと判断されたサイトにあるコンテンツも、ウェブ上の他のコンテンツを優先して表示すべきと判断されて、検索での掲載順位が下がります。そのため、有用ではないコンテンツを削除することで、他のコンテンツのランキングが改善する場合があります。」
リンク分析システムとPageRank
Googleはさまざまなシステムを導入して、ページ間の相互リンクを理解し、ページの内容と、検索クエリに対してもっとも有益な情報を提供するページを判断しています。
その中でもPageRankは、Google がサービスを開始した当初から使用されているコアランキングシステムの一つです。
PageRankの研究論文「大規模なハイパーテキスト Web 検索エンジンの構造」
米国特許6,285,999「リンクされたデータベース内のノードをランク??付けする方法」
PageRankの仕組みは当時から大きく進化しており、コアランキングシステムの一部として機能し続けています。
ローカル ニュース システム
Googleは、「トップニュース」や「ローカルニュース」などの機能により、関連性の高い地域のニュース情報を特定して表示するためのシステムを導入しています。
MUM
MUM(Multitask Unified Model)は、言語の理解と生成の両方の機能を持つAIシステムです。
今は検索のランキング全般には使用されていませんが、COVID-19(新型コロナウイルス感染症)ワクチン情報の検索の改善や、強調スニペットのコールアウト表示の改善など、特定の用途で使用されています。
SEOのヒント
質の高い情報を見つけるための新しい方法では、次のように解説されています。
「最新の AI モデルであるマルチタスク統合モデル (MUM) を使用することで、システムはコンセンサスの概念を理解できるようになりました。ウェブ上の複数の質の高い情報源はすべて同じ事実に同意しています。(中略)同じものを説明するためにソースが異なる単語や単語を使用している場合でも、スニペットの語句について一般的なコンセンサスがあるかどうかを確認できます。」
ニューラルマッチング
ニューラルマッチングは、検索クエリやページで表現されるコンセプトを理解して、それらを相互に関連付けるためにGoogleが使用するAIシステムです。
オリジナルコンテンツシステム
独自のレポートなど、独自性の高いコンテンツが、単にそれを引用したものよりも検索結果で上位に表示されて、目立つようにするためのシステムです。
その一つが特別な正規マークアップのサポートです。
ページ制作者は、ページが数か所で複製されている場合に、rel="canonical" などのマークアップを使用することで、どれがオリジナルかをGoogleに明確に伝えられます。
削除ベースの降格システム
Google では、特定の種類のコンテンツを削除できるポリシーを設けています。
特定のサイトに関連する削除通知が大量に処理されている場合には、その状況もシグナルとして使用し、検索結果の改善に役立てられます。
具体的には、法的手段による削除、個人情報の削除があります。
パッセージランキングシステム
パッセージランキングシステムは、ウェブページの個々のセクション(パッセージ)を特定して、ページが検索にどの程度関連しているかをよりよく理解するために使用するAIシステムです。
RankBrain
RankBrainは、単語がコンセプトにどのように関連しているかを理解するためのAIシステムです。
コンテンツと他の単語やコンセプトとの関連を理解することで、検索に使われた単語がすべて正確に含まれていなくても、関連するコンテンツをより適切に表示できるようになります。
SEOのヒント
スペルミスや、文章の理解をBERT言語理解システムが行うことにより、クエリを理解し、そのクエリに関連する結果をランク付けする機能です。
信頼できる情報システム
権威性の高いページを表示して質の低いコンテンツの順位を下げるシステムや、質の高いジャーナリズムの順位を上げるシステムなど、複数のシステムがさまざまな形で機能して、可能な限りもっとも信頼性の高い情報が表示されます。
信頼性の高い情報が見つからない場合、あるいは、検索で得られる結果の全体的な質に関して高い信頼性を確保できない場合、急速に変化するトピックに関連したコンテンツに関する注意事項が自動的に表示されます。
SEOのヒント
結果の横にある3つの点をタップすると表示される「この結果について」では、Web ページにアクセスする前に検索結果に関する詳細なコンテキストを確認できます。
情報源が公開された時期、Wikipediaの情報、情報源や企業に関するオンラインレビュー、企業が別の団体に所有されているかどうか、システムで多くの情報が見つからない場合など、ソースに関する情報が表示されます。
レビューシステム
レビューシステムは、質の高いレビューコンテンツを高く評価することを目的としています。
質の高いレビューコンテンツとは、洞察に満ちた分析結果や独自の調査情報を提供するコンテンツ、および特定のトピックについて深い知識を持つ専門家や愛好者が書いたコンテンツのことです。
SEOのヒント
「レビューシステムは、アドバイスや見解、分析結果を提供するために書かれた記事やブログ投稿、ページ、もしくは同様の当事者による独立したコンテンツを評価するように構築されています。商品やサービスのページのレビューセクションにユーザーが投稿したものなど、第三者からのレビューは評価対象ではありません。」
レビューシステムの仕組み
サイト多様性システム
サイト多様性システムは、検索結果の上位に同じサイトから2つ以上のウェブページが表示されないようにして、1つのサイトが上位の結果を独占しないようにするものです。
ただし、特定の検索に対して特に関連性が高いとシステムにより判断された場合は2つ以上表示されることがあります。
サイト多様性システムは通常、サブドメインをルートドメインの一部として処理します。
つまり、サブドメイン(subdomain.example.com)とルートドメイン(example.com)から抽出したデータは、すべて単一の同じサイトからの情報とみなされます。
ただし、関連性が高いと判断された場合、多様性を確保するためにサブドメインが別のサイトとして処理される場合もあります。
スパム検出システム
Googleは、スパムポリシーに違反するコンテンツや行為に対処するために、SpamBrainなどのさまざまなスパム検出システムを導入しています。
これらのシステムは継続的に更新されており、進化する最新のスパム手法に対応できるようになっています。
SEOのヒント
Google ウェブ検索のスパムに関するポリシー
廃止されたシステム
廃止された以下のシステムは、後継のシステムの一部として組み込まれているか、コアランキングシステムの一部となっています。
Hummingbird
より適切で関連性の高いコンテンツを検索結果に表示させるハミングバードは、2013年8月にランキングシステム全体に加えられた大幅な改善です。
それ以降も、Googleのランキングシステムはこれまでと同様に進化し続けています。
Pandaシステム
高品質で独自性の高いコンテンツが検索結果に確実に表示されるように設計されパンダたシステムは、2011年に発表され、さらに開発されて2015年にはGoogleコアランキングシステムの一部となりました。
Penguinシステム
リンクスパム対策のために設計されたペンギンシステムは、2012年に発表され、2016年にGoogleコアランキングシステムに組み込まれました。
Bingウェブマスターガイドライン(Bing Webmaster Guidelines)日本語訳 |2023年12月03日
検索エンジンのシェアは長年、Googleが圧倒的です。
かつてはYahoo!JAPANのYSTが一定のシェアを確保していましたが、現在ではGoogleのアルゴリズムを採用しており、検索結果としては似たようなものになっています。
(ただし2025年の契約終了後にどうなるかは未定)
Bingは、マイクロソフトが提供する検索エンジンで、シェアは数%以内にとどまっています。
しかし生成AIであるChatGPT4を検索エンジンのチャット方式でのメニューに問い入れたため、存在感が増しています。
Bingの検索結果はGoogleとは少し異なります。
印象としては強いサイトが検索結果中にいくつも現れるなど、限られたサイトが優遇されている感じがします。
スパム判定がGoogleよりも厳しい印象を感じたこともありますが、定かではなく、巷の情報ではSNSとの連携効果が強いという噂もありますが実証されていません。
Bingウェブマスター ガイドラインの構成
「Bingウェブマスター ガイドライン」は、「BingWEBmaster Tools Help & How-To Center」の中の、「Content Guidelines」の章としてあります。
「Content Guidelines」は、次の章立てになっています。
Bing Webmaster Guidelines(Bingウェブマスターガイドライン)
Marking up your site: Overview(サイトのマークアップ:概要)
Page best practices(404ページのベストプラクティス)
Bingvideo feed guidelines(Bingビデオフィードのガイドライン)
Special announcement specifications(特別な告知の仕様)
Link building(リンクの構築)
PubHub Guidelines for Publishers(パブリッシャー向けのPubHubガイドライン)
公開は英語のみで、日本語での公開がないため、「Bingウェブマスター ガイドライン」を日本語に翻訳しました。
これらのうち、WEBサイト制作・運営者全般に参考になる章について日本語訳を掲載します。
ビデオフィードのほか、感染症などの特別の告知、ニュース提供者のPubHubへのフィード送信については、BingWEBmaster Tools Help & How-To Center」の中の、「Content Guidelines」原文を参照ください。
Bingの検索については、「Bing Webmaster Guidelines」が公開されています。
Bingウェブマスター ガイドライン
これらのガイドラインは、BingがWEBサイトを見つけ、インデックスし、ランク付けする方法を理解するのに役立つことを目的としています。
これらのガイドラインに従うと、Bingでのサイトのインデックス作成に役立ちます。
また、サイトを最適化して、Bingの検索結果で関連するクエリに対し、ランク付けされる機会を増やすことにも役立ちます。
「悪用行為」の章のガイダンスと「避けるべきこと」の章で示す例に特に注意してください。
ガイドラインに従うことで、WEBサイトがルールに従って動作し、Bingの検索結果から降格あるいは除外されることもあるスパムとして検出されなくなります。
Bingがサイトを検索してインデックスを作成する方法
Bingがすべてのページを見つけられるように支援します
サイトマップ:
サイトマップは、Bingが、WEBサイトのURLとコンテンツを検出するために不可欠な方法です。
サイトマップはWEB サイト上のURL、その他のファイル、画像やビデオなどのコンテンツに関する情報を提供するファイルです。
サイトマップは、サイト内で重要であると思われるページとファイルについて、クローラーに通知します。
ページの最終更新日などの追加情報も提供します。
BingがWEBサイト内のすべての関連URLとコンテンツを検出できるように、XMLサイトマップファイルを使用することを強く推奨します。
サイトマップファイルは、できるだけ最新の状態に保ってください。
リアルタイムか、少なくとも1日に1回更新してください。
これにより、WEB サイトからコンテンツが削除された後、古いURLやデッドリンクをタイムリーに削除できるようになります。
次の方法でサイトマップを Bingで利用できるようにします。
・Bingウェブマスターツールのサイトマップツールを使い、Bingに送信します。
・robots.txt ファイルに次の行を挿入し、サイトマップへのパスを指定します。
Bingがサイトマップを認識すると、Bingは定期的にクロールします。
サイトに重大な変更があった場合を除き、再度送信する必要はありません。
サイトマップの一般的なガイドライン:
・Bingは、XML、RSS、MRSS、Atom 1.0、テキストファイルなど、いくつかのサイトマップ形式をサポートしています。
・一貫したURLを使用してください。Bingは、リストされているとおりにURLのみをクロールします。
・サイトマップには正規URLのみをリストしてください 。
・WEB サイトに複数のバージョン (HTTP と HTTPS、またはモバイルとデスクトップ) がある場合、サイトマップ内で1つのバージョンのみを指定することをお勧めします。
・モバイルとデスクトップで独自のURLを用いる場合には、rel="alternate" 属性の注釈を付けてください。
・異なる言語または地域の複数のページがある場合、 サイトマップまたは HTML タグのいずれかでhreflangタグを使用して、代替URLを識別してください。
・コンテンツが最後に変更された日時を示すlastmod属性を使用してください。
・サイトマップの最大サイズは、非圧縮で50,000URL/50MB です。サイトが大きい場合は、大きなサイトマップを分割し、サイトマップインデックスファイルを使用して、個々のサイトマップをすべてリストすることを検討しましょう。
・robots.txtファイル内のサイトマップを参照してください。
・Bingがサイトマップをクロールしてからサイトマップを変更していない場合、サイトマップを再送信する必要もメリットもありません。
サイトマップを使用しても、サイトマップ内のすべてのアイテムがクロールされ、インデックスが作成されることは保証されません。
ただし、ほとんどの場合、サイトマップはクローラーに推奨事項やガイダンスを提供するため、サイトマップを使用すると有益です。
IndexNow API、 BingURL、または Content Submission APIの使用
IndexNow API、 BingURL、または Content Submission APIを使用して、WEB サイトの変更を即座に反映します。
API を導入できない場合は、 Bingウェブマスターツールを介して直接、またはサイトマップに含めることによって、更新されたURLを送信するのがおすすめです。
リンク:
リンクは伝統的に、WEBサイトの人気を決定するシグナルとみなされています。
他のサイトに、自分のサイトへのリンクを設置してもらう最良の方法は、ユニークで高品質な独自のコンテンツを作成することです。
Bingのクローラー (Bingbot) は、WEB サイト内のリンク (内部リンク) または他のサイトからのリンク (外部リンク) をたどり、Bingが新しいコンテンツや新しいページを発見できるようにします。
Bingでは、サイト上のすべてのページを、少なくとも1つの他の検出可能でクロール可能なページからリンクすることをお勧めします。
・クロール可能なリンクは、 href属性のあるaタグです。
・参照リンクには、ページに関連するテキストか、画像のalt属性が含まれていなければなりません。
・ページ上のリンクの数を適切な量に制限し、ページごとに数千リンクを超えないようにしてください。
・サイト上の有料リンクまたは広告リンクが確実に使用されるよう合理的な努力をしてください。
rel="nofollow"かrel="sponsored"あるいはrel="ugc"属性を使用して、リンクがクローラーによって追跡されたり、検索ランキングに影響を与えたりするのを防ぎます。
・Bingは、自然に成長したリンクに報酬を与えます。
他の信頼できる関連WEBサイト上のコンテンツ作成者によって、時間の経過とともに追加されたリンクは、実際のユーザーをそのサイトからあなたのサイトに誘導します。
内部と外部の両方で有機的な方法でリンクを構築することを計画します。
リンク スキーム (リンク ファーム、リンク スパム、過剰なリンク操作) に参加するリンク購入など、インバウンド リンクの数と性質を水増しすることを目的とした不正な戦術は、サイトがペナルティを受け、Bingインデックスから除外される可能性があります。
WEBページの数を制限する:
WEBサイトのページ数を適切な数に制限します。サイト内で重複したコンテンツを避けてください。以下の方法で重複コンテンツの排除をしましょう。
・Canonicalタグを使用して、同じコンテンツを持つ異なるURLを出力しないようにします。
・WEBサイトとURLパラメーターを整理すると、クロール効率が向上し、同じコンテンツを指す同じURLの複数のバリエーションを減らすことができます。
モバイル固有のURLは避けてください。デスクトップ ユーザーとモバイルユーザーに同じURLを使用してみましょう。
必要に応じてリダイレクトを使用する:
WEBサイト上のコンテンツを別の場所に移動する場合、少なくとも3か月間は301リダイレクトを使用します。
移動が一時的な場合、つまり1日未満の場合は、302リダイレクトを使用します。サイトのコンテンツがある場所から別の場所に移動したときに、適切なリダイレクトの代わりにrel=canonicalタグを使用することは避けてください。
Bingのクロールを増やす:
ウェブマスターツールのクロールコントロール機能を使用すると、いつ、どのようなペースでBingbotがコンテンツをクロールするかを管理できます。
BingbotがWEBサイトを迅速かつ詳細にクロールできるようにして、できるだけ多くのコンテンツが検出され、インデックスが作成されるようにすることをおすすめします。
JavaScript:
BingはJavaScriptを処理できますが、HTTP要求の数を最小限に抑えつつ JavaScriptを大規模に処理するには限界があります。
Bingでは、特に大規模なWEBサイトに対して、クライアント側で、Bingbotのような特定ユーザーのために、レンダリングされたコンテンツと事前レンダリングされたコンテンツを切り替えられる動的レンダリングを推奨しています。
"404 Not Found"コードを返してコンテンツを削除します
Bingコンテンツ削除ツールとページ削除ツールを使用して、コンテンツを迅速に削除します。
コンテンツ削除リクエストは最大90日間有効で、更新する必要があります。
更新しないと、コンテンツが検索結果に再度表示される可能性があります。
robots.txt:
robots.txt ファイルは、Bingbotなどの検索エンジンクローラーに、サイト上でクローラーがアクセスできるページとファイル、またはアクセスできないページとファイルを通知します。
Robots.txtは、主にクローラーへのトラフィックの指示と管理のために使用されます。
たとえば、検索結果ページやログインページなど、あまり役に立たないコンテンツをクロールしないようBingbotに指示することが可能です。
・robots.txtは、WEBサイトのルート ディレクトリ (最上位のディレクトリ) に配置します。
サブディレクトリには置かないでください。
・Bingによるページのクロールをブロックすると、そのページがインデックスから削除される可能性があります。ただし、Disallowを使用しても、ページがインデックスまたは検索結果に表示されなくなるという保証はありません。特定のページのクロールやインデックス作成をブロックしたい場合には、robots.txt で禁止するのではなく、noindexのようなrobotsメタタグを使用する必要があります。
・robots.txtを頻繁に見直して、最新であることを確認してください。
Bingウェブマスターツールで robots.txtにより禁止されているURLを確認し、正確な値が保たれていることを確認します。
・robots.txt テキストファイルの作成方法を読んで、詳細を確認してください。
リソースの節約:
HTTPの圧縮と、条件付き取得を使用して、ページの読み込み速度を向上させながら、クローラーとユーザーが使用する帯域幅を削減します。
Bingがページを理解できるようにする
Bingは、検索エンジンではなくユーザー向けに作成された、リッチで価値のある魅力的なコンテンツを求めています。
WEBサイト上に、明確でユニーク、高品質、関連性があり、見つけやすいコンテンツを作成すると、Bingのインデックスに登録され、検索結果にコンテンツが表示される可能性が高まります。
コンテンツ:
コンテンツが少なく、広告やアフィリエイト リンクを主に表示するWEBサイト、訪問者を他のサイトにリダイレクトするWEBサイトは、Bingでのランキングがすぐに低下する傾向があります。
場合によっては、インデックスがまったく作成されないこともあります。
コンテンツは、WEBサイト訪問者にとってナビゲートしやすく、内容が豊富で魅力的で、彼らが求める情報を提供しなければなりません。
・検索エンジンではなく、検索ユーザー向けのコンテンツを作成する:
検索ユーザーがどのような情報を探しているかを示すキーワード調査に基づいて、リッチコンテンツを開発します。
・訪問者の期待に完全に応えるのに十分なコンテンツを作成します。
1ページあたりの単語数について厳密なルールはないものの、一般的に、より関連性の高いコンテンツを提供する方が良いでしょう。
・ユニークなものにして、他のソースからのコンテンツを再利用しないでください。
ページ上のコンテンツは、最終的な形式では一意である必要があります。
サードパーティからのコンテンツを掲載する場合には、rel="canonical"で元のソースを特定するか、rel="alternate"で代替タグを指定するなど、正規化タグを使用します。
・画像とビデオ:ページのトピックに関連した、ユニークでオリジナルの画像とビデオを使用します。Bingは、画像、キャプション、構造化データ、タイトル、トランスクリプトなどの関連テキストから情報を抽出できます。
画像やビデオ内に重要なテキストや情報を埋め込まないでください。
光学式文字認識はHTMLテキストよりも信頼性が低く、アクセスできません。
altテキストは、ページ上の画像を表示できない人やデバイスのアクセシビリティを向上させます。
altテキストを使うときは、キーワードを適切に使用して、ページのコンテンツに関連する画像に意味を与える情報豊富な内容でを作成することに重点を置きます。
画像やビデオには、わかりやすいタイトル、ファイル名、テキストを含めます。
ビデオはサポートされている形式で、ペイウォール保護やログインでブロックされていないことが必要です。
字幕とキャプションをビデオに使用すると、より多くの視聴者が利用できるようになり、検索エンジンにビデオファイルとオーディオファイル内のコンテンツのテキスト表現が提供されます。
高品質の写真とビデオを選択してください。ぼやけた画像や焦点の合っていない画像よりも、ユーザーの興味を引き付けます。
・画像とビデオを最適化してページの読み込み時間を短縮します。
多くの場合、画像はページサイズとページ読み込み速度の低下に、もっとも大きく影響します。
・セーフサーチは、検索結果に露骨な画像、ビデオ、WEB サイトを表示するか、非表示にするかを指定する設定です。
Bingは機械学習を使用して、画像を分類します。
もっとも強力なシグナルは、成人向けのページとコンテンツを自己マークしたものです。
meta name ="rating" content="adult"を使用して、Bingが成人向けの画像とコンテンツを理解できるようにするのがおすすめです。
成人向け画像を、共通のファイルフォルダーにグループ化することも有効です。
・コンテンツを見つけやすくします。
FlashまたはJavaScript内に、コンテンツを格納することはやめましょう。
これらは、クローラーによるコンテンツの検索をブロックします。
・すべてのサイト訪問者にとってコンテンツにアクセスし、簡単にナビゲートできるようにします:
スクリーンリーダーなどのデバイスの使いやすさをテストします。
コンテンツを見るのではなく、聞くと目を見張るものがあり、画像やビデオの代替テキストの正確さと品質を確認するのに役立ちます。
ユーザビリティのテストは、WEB サイト内のナビゲーション、読む順序、表のマークアップ、フォーム要素に関する問題を特定するのにも役立ちます。
HTMLタグ:
HTML要素とalt属性が、説明的、具体的、正確であることを確認します。
titleタグ
ページのタイトル。WEB サイトの各ページに、説明的でユニークなタイトルを付けます。
eta name="description"
これはWEBページの概要と説明であり、検索結果にページの説明として表示されることがあります。
このスペースを使用して、titleタグをさらに拡張する関連する説明を書きます。
meta name="robots"
これらを使用して、特定のページ コンテンツのインデックス作成に関するクロール指示をクローラーに与えられます。
robotsメタタグを使用すると、スニペットとコンテンツプレビューの設定をBingに知らせることができます。
a hrefタグ
別のページにリンクするURLを指定します。
同じページ内の別の部分にリンクする場合は、#タグを使用します。
img srcタグ
表示する画像ファイルを指定します
alt属性
img画像を説明するタグに、この属性を使用します。
alt属性で説明的で情報豊富なコンテキストを使用して、画像に意味を付加できます。
h1タグ
適切に使用すれば、ユーザーがページのコンテンツをより明確に理解できるようになります。
h1-h6見出しタグ
ページの構造を定義し、Bingが各段落の内容を理解できるようにします。
pタグ
段落を区切ります。
tableタグ
tableやthタグはデータテーブルの場合などに使用し、レイアウト用に使用してはなりません。
ブラウザ、開発者、検索エンジンにとって本質的な意味を持つ、HTML5セマンティック要素を使用します。
特に、次のHTML5セマンティック要素を使用します。
article, aside, details, figcaption, figure, footer, header, main, mark, nav, section, summary, time
URL検査ツールや、マークアップ検証サービスを使用して、HTMLを検証します。
Microsoft Edge :
Microsoft Edgeブラウザで、WEBページが壊れて表示されないことを確認してください。
ドキュメントが読み込まれると、検索可能なコンテンツが表示される必要があり、ページの読み込み時にポップアップがあってはなりません。
二次コンテンツ (CSS、JavaScript) :
robots.txtでクローラーを許可します。
すべてのCSSスタイル シートと JavaScriptファイルをクロールします。
リソースの動的読み込みの使用は制限します。
つまりAJAXを使用して、HTTPリクエストの数を制限し、大規模なWEBサイトでのJavaScriptの使用を制限します。
構造化データのマークアップを使用して、 Schema.org、RDFa、またはOpenGraph形式の、ページに関する情報を伝えます。
JSON-LD、またはMicrodata 形式のSchema.orgが推奨されます。
セマンティックマークアップにより、Bingの豊富な機能に利用されることがあります。
ただし、それを保証するものではありません。
URL検査を使用して、ページ上のスキーマ マークアップを検証します。
悪用行為と避けるべきことの例
検索エンジン最適化は、WEBサイトの技術面とコンテンツ面を改善し、検索エンジンのクローラーが、関連するコンテンツを見つけ、アクセスしやすくすることを目的とした正当な手法です。
ほとんどのSEO施策では、WEB サイトをBingにとってより魅力的なものにします。
ただし、SEO関連施策を実行しても、ランキングが向上したり、Bingからのサイトのトラフィックが増加したりすることは保証されません。
さらに極端に言うと、一部のSEO 手法が悪用され、検索エンジンからペナルティを受ける可能性があります。
Bingウェブマスター ガイドラインでは、もっとも蔓延する不適切な行為、操作的な行為、誤解を招く行為の一部のみについて説明しています。
以下に概説するような不正行為に関与するサイトは、低品質とみなされます。
その結果、これらのサイトはランキングペナルティを被ったり、サイトのマークアップが無視されたり、インデックス作成に選択されなかったりするかもしれません。
Microsoftは、ここに記載されていない行為であっても、サイトに対する不適切または欺瞞的な行為に対して措置を講じる場合があります。
サイトに対して何らかの措置が講じられていると思われる場合は、Bingウェブマスターツールを通じて、サポートチームにご連絡ください。
さらにユーザーは、問題を再現する検索を実行した後、bing.com のフッターにあるフィードバック を使用して、これらの行為の悪用を報告できます。
この例はここで見ることができます。
クローキング:
クローキングとは、WEB ページの1つのバージョンを、Bingbot などの検索クローラーに表示し、別のバージョンを通常の訪問者に表示する手法です。
クローラーが見ているものとは異なるコンテンツをユーザーに表示すると、スパム戦略とみなされる可能性があり、WEB サイトのランキングに悪影響を及ぼし、Bingインデックスからサイトが除外される可能性があります。
WEB サイトは、通常の訪問者とは対照的に、クローラーに対して異なる対応を行うことについて細心の注意を払う必要があり、原則としてクローキングを使用すべきではありません。
リンクスキーム、リンク購入、リンクスパム:
リンク スキームは、WEBサイトに向けられたリンクの数を増やすことには成功したとしても、サイトに質の高いリンクをもたらすことはできず、サイトに何のプラスの利益ももたらしません。
インバウンドリンクを操作して、WEBサイトに向けたリンクの数を人為的に増やすと、サイトがBingインデックスから除外される可能性があります。
ソーシャル メディア スキーム:
ソーシャルメディアスキームは、ネットワーク効果を人為的に利用して、Bingのアルゴリズムをゲーム化しようとする点で、リンクファームに似ています。
現実には、ソーシャルメディアのスキームは実際に行われているのが簡単に確認でき、WEBサイトの価値は下がります。
その一例が自動フォローです。
自動フォローは、Twitter などのソーシャルサイトでのフォロワーの増加を促進し、フォローしている人を自動的にフォローすることで機能します。これにより、時間の経過とともに、あなたのフォロワー数が、あなたをフォローしている人の数とほぼ同じになるというシナリオが作成されますこれはあなたが強い影響力を持っていることを意味するものではありません。
フォローしている人が少なく、フォロワー数が多いということは、発言力が強いことを意味します。
重複したコンテンツ:
複数のURL間でコンテンツが重複すると、時間の経過とともに、BingがそれらのURLの一部に対する信頼を失う可能性があります。
この問題は、問題の根本原因を修正することで対処する必要があります。
rel=canonical要素も使用できますが、核心的な問題を解決するための二次的な解決策として考慮する必要があります。
過剰なパラメータ化が重複コンテンツの問題を引き起こしている場合には、URL検査ツールを使用することをおすすめします。
スクレイピングされたコンテンツ:
より評判の高い他のWEBサイトから、コンテンツをスクレイピングまたはコピーすると、ユーザーに価値が付加されず、著作権侵害とみなされる可能性があります。
オリジナルのコンテンツや価値を追加せずに、他のサイトからコンテンツを再公開するのではなく、WEBサイトを差別化するオリジナルのコンテンツを作成しなければなりません。
他のWEBサイトのコンテンツをわずかに変更して再公開することも、スクレイピングに該当します。
キーワードの詰め込み、または無関係なキーワードを含むページの読み込み:
コンテンツを作成するときは、検索エンジンによるコンテンツのランク付けのためではなく、現実のユーザーや読者を対象にコンテンツを作成しましょう。
特定の検索語でのランキングの確率を人為的につり上げることのみを目的として、コンテンツに特定のキーワードを詰め込むことは、ガイドラインに違反します。
これにより、あなたのWEBサイトが降格され、あるいは検索結果から除外される可能性があります。
自動生成コンテンツ:
自動生成コンテンツは、人間の積極的な介入なしに、自動化されたコンピュータープロセス、アプリケーション、またはその他のメカニズムによって生成される情報です。
このようなコンテンツは悪意あるものとみなされ、通常、上位のランキングを飾り立てるためだけに作成された意味のないテキストが含まれています。
この種のコンテンツはペナルティの対象となります。
十分な価値を付加しないアフィリエイトプログラム:
他のWEBサイト (Amazon、eBay など) から商品をリンクしているにもかかわらず、正規小売店であるか、またはそれらのサイトと提携しているかのように装うWEBサイトは、シンアフィリエーションサイトと呼ばれ、ほとんど付加価値がないか、追加のレビュー、検索機能、編集者の選択などの価値の増加がなく、他のコンテンツの功績を称えることのみを目的としています。
これにより、あなたのWEBサイトが降格され、あるいはの検索結果から除外される可能性があります。
悪意のある行為:
コンテンツを作成してサイトを管理するときは、コンテンツを確認し、CMSを維持し、オペレーティング システムを最新の状態に保ち、フィッシングやウイルス、トロイの木馬、その他の悪質なソフトウェアのインストールをせず、あなたのサイトで公開できるアクセスを制限してください。
悪意ある行為は、あなたのWEBサイトを降格し、あるいは検索結果から除外したりする可能性があります。
誤解を招く構造化データのマークアップ:
構造化データマークアップを含むサイトは、タグが配置されているページを正確に表している必要があります。
サイトには、ページに無関係で、不正確または誤解を招くマークアップを含めてはなりません。
Bingがコンテンツをランク付けする方法と、Bingのその他の検索エクスペリエンスについては、「Bingによる検索結果の提供方法」をご覧ください。
サイトのマークアップ: 概要
Bingでは、ユーザーが視覚的に魅力的で、情報が豊富な検索結果を通じて、重要な意思決定を行えるようにすることが、検索体験での重要な要素です。
コンテンツ公開者は、次のサポートされている仕様のいずれかを使用して、構造化コンテンツに注釈を付けることで、この検索に貢献し、目立たせることができます。
- Schema.org :HTML Microdata、JSON-LD
- Microformats
- RDFa
- Open Graph
クローラは、特定の仕様を、別の仕様より優先することはありません。
サポートされている仕様のどれがデータに最適であるかを決定するのは、完全にユーザー次第です。
通常、WEB マークアップの基本を理解していれば、注釈を実装できます。
データに注釈を付けても、実際に表示されるコンテンツは変更されないものの、るコンテンツの種類に関する貴重な情報が Bingに提供されます。
注釈は、検索結果の視覚的な魅力を高めるために使用され、あういはデータソースを補足、検証するなど、有効に活用されます。
たとえば、住所の注釈を使用すれば、Bingで次の検索結果が表示されることがあります。

Bingは現在、次のシナリオの注釈をサポートしています。
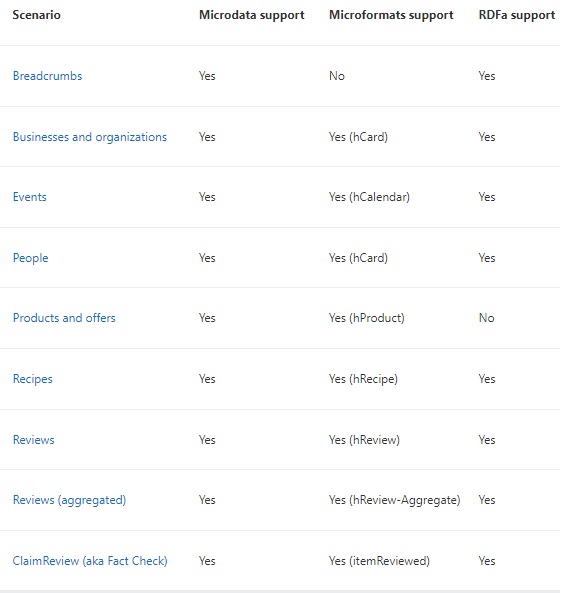
パンくずリスト(Breadcrumbs)
企業や団体(Businesses and organizations)
イベント(Events)
人々(People)
製品とオファー(Products and offers)
レシピ(Recipes)
レビュー(Reviews)
レビュー(集計)(Reviews (aggregated))
事実調査 (別名ファクトチェック)(ClaimReview (aka Fact Check))
注記
Bingは、次の2つの追加の注釈タイプを理解します。
・Schema.org は、さまざまなデータ型をカバーする、従来のMicrodataによる注釈の拡張機能です。
Schema.org のデータ型は、これらのページで説明されているMicrodataとは異なりますが、ここで説明されている注釈技術はSchema.orgの注釈に適用できます。
・Open Graphプロトコルで指定されているページレベルの注釈ですが、現在この情報は、限られた数の発行者の検索結果の視覚的表示を強化するためにのみ使用されます。
1. Open Graph プロパティを使ったBingニュースの使い方:
サイトに画像のOpen Graphプロパティが含まれている場合、Bingニュースは、PC およびモバイルでのBingニュースの検索結果に対して、Open Graph 画像メタタグ内で指定したピクセルサイズで、その画像を表示することがあります。
2. Open Graph画像メタタグ内で指定されたピクセルサイズの画像の使用を、Bingニュースで停止する方法:
SOCIALONLYメタタグを追加して、Bingニュー クローラーが、PCとモバイル上のBingニュース検索結果に、その画像を表示しないようにすることができます。
留意すべき事項
注釈が存在するだけでは、Bingが注釈付きコンテンツを使用して、視覚的にリッチなスニペットを生成することは保証されません。
注釈が付けられたコンテンツとその周囲との関係は、常に考慮されます。
注釈を実装すると、Bingクローラーは次回、ページにアクセスしたときに注釈を取得します。
上記の関連性の検証に加えて、さまざまな理由により、視覚的に充実した検索結果がサイトに表示されないことがあります。
スキーマとデータ検証の失敗
注釈をサイトに公開する前に、注釈を注意深く確認してください。
Bingクローラーは、選択した形式で指定されたスキーマと、指定されたデータ型に対して、注釈付きデータを検証します。
たとえば、価格が日付である場合、またはその逆の場合、クローラーは注釈を無視します。
同様に、十分なデータが提供されていることを確認してください。
日付のないイベントや、名前のない人物も無視されます。
グローバルな可用性
注釈はすべての市場で処理および検証されますが、視覚的にリッチなスニペットは現在、すべての市場でサポートされているわけではありません。
構造化データは、この機能の世界的な展開を計画する際に、適切な市場に優先順位を付けるのに役立ちます。
404 ページのベスト プラクティス
404ページは、ページが見つからないか、ユーザーが壊れたリンクをクリックしたときに表示されるエラーページです。
これらのページには、「ページが見つかりません」などのメッセージ以外のコンテンツが、ほとんど含まれていないことがよくあります。
404ページは、クリックしたリンクまたはリソースが、利用できない、またはもう利用できないことをユーザーに通知し、WEBサイト内の他のコンテンツに誘導するように設計されています。
404 ページを作成する際に留意すべき点がいくつかあります。
1. いかなる種類の広告も禁止
1 すべてのエラーページには、広告モジュールなどのサービス呼び出しが含まれていてはなりません。
これは404ページが静的HTMLであり、複雑なスクリプト、広告、またはページ自体からサービスを呼び出すようなものを一切含まないことを意味します。
これは、要求されたリソースが適時に返されず、プラットフォームの整合性が失われる (サーバーがクラッシュする) リスクがあるためです。
2 404ページで体験されるボリュームが少ないことと、ユーザーを WEB サイト内の他のコンテンツに案内するという目的、および「エラー」ページとして機能するという目的と組み合わせると、404ページに広告を挿入することは、ユーザーエクスペリエンスにとって有益ではないことを意味します。
広告があってもクリックされる率は低いため、多く閲覧されることによる全体的な広告収益と価値が、低下する可能性は低いといえます。
3 広告には、元のページのコンテンツに関連する検索結果を返すことができる自動ウィジェットの挿入が含まれます。
このようなウィジェットは最終的にクロールされ、検索結果に表示されるアイテムのループを作成し、それ自体が404エラーページを返す可能性があります。
これにより検索クローラーが損傷を受け、今後サイトを回避するようになり、サーバーにも損害を与える可能性があります。
2. ページが404ステータスコードを返す
SEOの観点から404ページは、200 (OK) ステータスコードではなく、404ステータス コード (ページが見つかりません)を返す必要があります。
404ステータス コードが返されると、検索エンジンクローラーなどの自動ユーザーに、リンクが切れていることが警告されます。自動化されたユーザーがこれを確認できる唯一の方法です。
404ページが200ステータス コードを返してしまうと、検索エンジンは、壊れたリンクが有効であると判断し、404ページがインデックス登録されてしまう可能性があります。
3. 「スマート」404ページ
1 上述したように、404ページの目標は2つあります。
まず、コンテンツが利用できなくなったことを訪問者に警告します。
次に、訪問者のWEBサイトへの関心を維持するために、他のコンテンツオプションを提供することです。
2 404ページには、訪問者がWEBサイト全体で関連コンテンツを見つけるためにクリックする可能性のある、他のオプションが表示されるため、WEBサイトの視覚的なレイアウトに一致させることは許容されます。
一部のWEBサイトでは、訪問者のWEBサイトへの関心を維持するため、もっとも人気のあるコンテンツへの一連のリンクを404ページに表示しています。
3 いずれの場合も、404ページが軽量で、すぐに読み込まれるようにしてください。
「スマート」404ページであっても、ページ内のモジュールにデータを取り込むサービスへの外部呼び出しは避けましょう。
ページ自体に情報を直接格納します。
リンクの構築
リンク構築とは、WEB サイトとの関係を構築して、他のWEBサイトから、WEBサイト内のページへのリンクを取得する方法です。
このようなリンクはバックリンクと呼ばれます。
Bingはリンクが有機的に、つまり自然に 構築されることを好みます。
これは、人々があなたのコンテンツがユニークで高品質であると認識するにつれて、リンクが徐々に構築されることを意味します。
あなたのサイトが信頼できる、権威のあるコンテンツを提供しているとみなされるため、リンクは検索エンジンにとって重要なシグナルです。
自分のWEBサイトを考えてみてください。リンクするのは、信頼でき、訪問者にとって役立つとわかっているソースのみです。
このような有機的なリンクは、インターネットが「ウェブ」になるのに役立ちました。
オーガニックリンクは、ソーシャルメディア上で何かが「広まる」原因となることがよくあります。
コンテンツが人気化すれば、そのコンテンツに向けられるリンクの数が劇的に増加します。
検索エンジンは、そのようなリンクを価値のあるコンテンツの称呼と見なします。
リンクを探すときは、BingがあなたのWEBサイトぬ向けられた、質の高いリンクを確認したいことに注意してください。
高品質のリンクとは、Bingがすでに認識し、信頼しているWEBサイトからのリンクです。
信頼できるサイトからのリンクを取得するには、大変な作業が必要ですが、価値のあるコンテンツをユーザーに提供し、WEBサイトで他のユーザーにリンクを共有するという一貫したパターンに従っていると、信頼できるリンクがWEBサイトに集まりはじめます。
リンクを構築する他の方法は、次のとおりです。
相互リンク
相互リンクでは、他のWEBサイトとリンクを交換することに同意したことになります。
他サイトからあなたのサイトに1つのリンクが向けられ、あなたのサイトからも1つのリンクが向けられます。
Bingはそのようなリンクを簡単に見破ることができ、こうしたリンク交換には限定された価値を割り当てます。
ただし、有効なリンク構築戦略として、これを無視しないでください。
新しいWEBサイトにはリンクが必要であり、リンクを交換することは、信頼できるリンクを獲得するための優れた方法であり、他のWEBサイトから直接トラフィックを獲得できる可能性があります。
トラフィックが増加すれば、新しい訪問者がWEBサイトの情報を広め、より多くのリンクを獲得するのに役立ちます。
リンクの購入
信頼できるWEBサイトからリンクを購入することもできます。
しかしBingでは、WEBサイトからのリンクが毎月、外されては、その後1か月間ほど新しいリンクがWEBサイトに向けられるというパターンを簡単に確認でき、WEBサイトがリンクを購入していることを判別します。
WEBサイトから外されるリンクは、すべて疑わしいものになります。
検索エンジンはパターンを認識することに優れているため、検索ランキングを上げるためのリンクを購入する前に慎重に検討してください。
ただし、閲覧者の多くWEBサイトからのリンクを購入すると、直接トラフィックが得られるため、リンクを購入することは依然として有効なマーケティング戦略です。
Bingがオーガニックランキングに影響を与えるために、リンクを購入しているという印象を与える可能性があるため、この戦略を採用する頻度には注意してください。
リンクファーム
私たちはこの用語を、オーガニック検索のランキングを操作する目的で、サイトへのリンクをするように設計された、あらゆる形式のリンク共有スキームを指すためにおおまかに使用しています。
一般的なリンクファームには、WEB サイトへのリンクが何百、何千もあり、多くの場合、かつては上位にランクされていたものの現在は休眠状態になっている古いドメインからのものです。
3方向のリンク交換も、同様のものに該当するため、避けるべきです。
リンクが潜在的に危険であると疑う場合、展示会でBingの担当者に会った場合、その人にそのリンクについて伝えることを躊躇するかどうかを自問してください。
リンクの構築方法
正規のインバウンドリンクを構築する最良の方法は、高品質で独自のコンテンツを作成することです。
優れたコンテンツの信頼できるソースとして知られるようになれば、訪問者は自然にあなたのWEBサイトへのリンクを共有するようになります。
ソーシャル共有によってこの方法がさらに強化されるため、訪問者がサイト内で気に入ったものを簡単に共有できるようにしてください。
次の方法で共有を促進することができます。
・ユニークで魅力的なコンテンツを構築します。
・訪問者向けのソーシャル共有オプションを有効にします。
・コードスニペットのコピーアンドペーストを有効にして、訪問者がコードをすばやく取得して、サイトからWEBページへのリンクを作成できるようにすることを検討してください。
リンクを希望するWEBサイトを探して、あなたのサイトにリンクするかどうかを尋ねることもできます。
適切な連絡先情報を明らかにするにはある程度の作業が必要ですが、礼儀正しく、当然の要求があなたに有利に働く可能性があります。
もう1つのオプションは、ゲストブログの執筆を提供することです。
多くのWEBサイトやブログでは、独自のコンテンツや記事と引き換えに、WEBサイトへのリンクを提供します。
その前にある程度の信頼を確立する必要があるため、他のサイトにアプローチして、ゲストブログの執筆を申し出る前に、そのトピックの専門家としての信頼を築いてください。
あなたの仕事が気に入られれば、良い仕事をできる機会について話してくれるかもしれません。
ただし、あなたが好印象を与えることができなかったり、卑劣なことを試みたりした場合、彼らはそれについてブログに書くでしょう。
信頼できるリンクを取得するための、信頼できる場所であるディレクトリを調べることもできます。
ディレクトリは依然として重要ですが、それだけではWEBサイトのランキングが向上しないことに注意してください。
質と量
WEBサイトがリンクを購入していることを、検索エンジンに警告するもっとも早い方法は、1日に10,000 の新しいリンクを公開することです。
何千ものリンクがもらえるサービスに登録したくなるかもしれませんが、これは避けるべきです。
Bingは、あなたのWEBサイトに向けられた質の高いリンクを確認したいと考えています。
信頼できるWEBサイトからのインバウンドリンクがいくつかあるだけでも、ランキングを上げるのに十分です。
コンテンツと同様に、リンクに関しても、品質がもっとも重要です。
Google「検索エンジンスターターガイド」をSEO施策別に解説 |2023年12月03日
SEOには大きく分けて、外部SEO対策、内部SEO対策、コンテンツSEO対策があります。
ただし厳密には分類できない施策もあります。
たとえば内部SEO対策には、技術的なSEOもある一方、コンテンツSEOに近い施策もあります。
SEOを行うには、次の情報を参考にするのがよいでしょう。
- 検索エンジンが開示・提供する方針やガイドライン
- アクセス解析やキーワードツール、SEOツールから得られるデータ
- 検索エンジンが開示・提供するニュースリリースやブログ、SNS投稿等
検索エンジンが開示・提供する方針やガイドライン
検索エンジンの公式のガイドラインとしては、Googleでは「検索エンジン最適化(SEO)スターター ガイド」、Bingでは「Bingウェブマスターガイド」などが知られています。
その他のリソースとしては、次のものがあります。
Google 検索セントラルのブログ
Google 検索セントラルの Twitter
Google 検索セントラルの YouTube チャンネル
ここでは、SEOの第一歩として目を通しておくべき「検索エンジン最適化(SEO)スターター ガイド」について、外部SEO対策、内部SEO対策、コンテンツSEO対策に分類して解説します。
「検索エンジン最適化(SEO)スターター ガイド」の対象読者は、「企業の経営者、いくつものウェブサイトの所有者、ウェブ代理店の SEO 専門家、Google 検索の仕組みを学んで SEO を改善したいとお考えの個人の方など」とされています。
SEO会社に依頼する場合でも、WEB事業の担当者、経営陣、個人のWEB管理者などは、内容をよく知っておくのが良いでしょう。
Googleのおすすめの方法を知り、それに基づいてWEB制作、コンテンツ制作を行うことが、SEO効果を高めるための重要な参考になるでしょう。
「検索エンジン最適化(SEO)スターター ガイド」に基づく外部SEO対策
Google Search Consoleにサイトを登録する
「検索エンジン最適化(SEO)スターター ガイド」の「サイトを Google に表示するには」では、
「Google Search Console では、コンテンツを Google に送信し、Google 検索での状況を確認するためのツールを提供しています。」
として、WEBサイトを登録することを推奨しています。
Google Search Consoleを使えば、次のことがわかります。
- 所有するウェブサイトが Google に表示されているか?
- ユーザーに質の高いコンテンツを提供しているか?
- 所有するローカル ビジネスが Google に表示されているか?
- ウェブサイトのコンテンツにどのデバイスからでも速く簡単にアクセスできるか?
- 所有するウェブサイトは安全か?
サイトマップの送信
スターターガイドの「Google がコンテンツを見つけられるようにする」では、最適な方法としてサイトマップの送信をあげています。
サイトマップとは、サイト上の新しいページまたは変更されたページについて検索エンジンに伝えるための、たとえば「index.xml」「sitemap.xml」のようなファイルです。
詳しくは、サイトマップを作成して送信する方法を確認し、WEBページがGoogleにインデックスされやすくなるようにしましょう。
クロールさせたくないページをrobots.txtで検索エンジンに伝える
robots.txtを使って、GoogleやBingなどの検索エンジンのクローラを制御することができます。
アクセスされたくないページは、robots.txtに記述することで、ブロックすることが可能です。
robots.txtは、WEBサイトのルートディレクトリに配置します。
また、chatGPTなどの学習にWEBサイトのデータを利用されたくない場合の制御を記述することもできます。
記述例
User-agent: googlebot
Disallow: /admin/
Disallow: /cgi-bin/
検索エンジンの検索結果に表示してほしくないページや、意味のないページやディレクトリは、robots.txtでクロールされないようにするとよいでしょう。
その他の方法では、ページごとのhead内にnoindexタグやnofollowタグを使用する方法、高いセキュリティが必要なディレクトリはベーシック認証などで保護する方法があります。
被リンク
スターターガイドの「ウェブサイトを宣伝する」においては、
「サイトへのリンクの大部分は、ユーザーが検索やその他の方法でコンテンツを発見してそのコンテンツにリンクするにつれて、徐々に増えていきます。」
としています。
外部からの被リンクは、今日でもSEOにおいて重要な施策です。
しかし不自然な被リンクなどはスパムとして扱われるリスクがあり、「スパムに関するポリシー」で説明されています。
スターターガイドでも、「避けるべき事項」として、
「自分のトピック分野に関連するすべてのサイトに対してリンク リクエストをスパム的に送信する。」、
「PageRank の獲得を目的に別のサイトからリンクを購入する。」
ことがあげられています。
効果の高い被リンクは、自然に集まるリンク、関連あるサイトから張られるリンク、権威あるサイトから張られるリンクなどです。
自作自演リンクなどは検索エンジンに見破られやすいため、現在では基本的にはやらないほうがよいでしょう。
ただし自社で運営している別サイトから、ごく普通に自然に紹介するリンク程度は問題ありません。
自分で被リンクを集めるとすれば、下記の程度かと思われます。
- 自社の関連サイト、ブログ等からの過度ではないリンク
- 業界団体、グループ等、関連する精鋭サイトからのリンク
- Googleビジネスプロフィールや、地域の代表的なサイトからのリンク
- SNSなどからのリンク
作成したコンテンツを他の人に知らせる
スターターガイドでは、
「新しいコンテンツを効果的に宣伝すれば、同じテーマに関心を持っているユーザーに発見されるのが早くなります。」
としています。
一方で、
「ただし、このガイドでご紹介した他の注意点と同様に、以下のおすすめの方法を極端に行うと、実際にはサイトの評判を傷つける可能性があります。」
とも注意喚起しています。
WEBサイトのコンテンツを宣伝するには、SEOや広告のほか、SNS投稿が代表的です。
それ以外にも、オンラインコミュニティ、RSSフィード、メルマガ、オフラインでの宣伝を利用する方法などがあります。
スターターガイドの「避けるべき事項」では、次の項目があげられています。
- 新しい小さな分量のコンテンツを作成するたびに宣伝する(大きくて興味を引くコンテンツを宣伝しましょう)。
- コンテンツがソーシャル メディア サービスの上位に表示されるように人為的に操作する手法をサイトに適用する。
- サイトの関連コミュニティのユーザーにアプローチする
Googleビジネスプロフィールに登録する
Googleビジネスプロフィールは、企業や個人事業者が、ビジネスのプロフィールや所在地を登録し、googleマップ上に表示させるとともに、検索での露出が可能になるものです。
特に地域に密着した店舗や企業などの集客に効果的です。
Googleビジネスプロフィールでは、住所、電話番号などの連絡先のほか、営業時間や休日、メニューや価格、最新情報、写真、Q&Aなどの掲載や口コミの収集が可能です。
SNSでの情報配信
facebook、X(旧Twitter)、InstagramなどのSNS、YouTubeなどの動画配信サイトでは、自社の情報配信や、さまざまなコンテンツ配信ができます。
配信内容にWEBサイトの情報やURLなどを掲載できるほか、それぞれのSNSのプロフィール欄、概要欄などにも一定の情報が掲載できます。
SNSではユーザーとのコミュニケーションがとれるほか、他のユーザーによる言及を通じて情報の拡散が期待できます。
ユーザーによる言及を「サイテーション」といい、被リンクが得られないか、nofollowの付いた被リンクで直接的な被リンク効果は得られない場合でも、SEO効果があるとされています。
実際の集客やブランド価値の向上にも効果があるでしょう。
検索のパフォーマンスとユーザーの行動を分析する
SEO対策には、検索順位のチェックや、アクセス解析等によるユーザー行動の分析が不可欠です。
スターターガイドでは、次のように説明しています。
「Googleなどの主要な検索エンジンでは、ウェブサイトの所有者向けに、検索エンジンでのパフォーマンスを分析できるツールが提供されています。Google の場合は、そのようなツールとしてSearch Consoleをご用意しています。」
Search Consoleを使えば、Googleがページをインデックスしているか、外部からの被リンク、被リンクされているアンカーテキストなどの、外部SEO施策に有効な情報を確認することができます。
また、Search Console Insightsを使えば、WEBサイト内でアクセスされているページや、ユーザーが使った検索キーワードなどサイト集客の経路を知ることができます。
SEO対策は、施策の実施と、効果の検証の繰り返しともいえます。
Search Consoleでは、その他にも次のことが可能です。
- Googlebotがクロールできなかったサイトの部分を確認する
- サイトマップをテスト、送信する
- robots.txtファイルを分析、生成する
- すでにGooglebotにクロールされたURLを削除する
- 使用するドメインを指定する
- title と description meta タグを使用して問題を特定する
- サイトへのアクセスに使用された上位の検索クエリを把握する
- Google からのページの見え方を確認する
- スパムポリシー違反に関する通知を受け取り、サイトの再審査をリクエストする
なお、Microsoftが提供するBing Web マスターツールでも、同様に検索エンジンBingについての情報を得ることが可能です。
「検索エンジン最適化(SEO)スターター ガイド」に基づく内部SEO対策
検索エンジンとユーザーがページを読めるようにする
スターターガイドの「Google(とユーザー)がコンテンツを理解できるようにする」の項目では、検索エンジンがデータを収集するためのGooglebot がページをクロールするときに、平均的なユーザーが見るのと同じ状態でページを参照できる必要があるとしています。
最適なレンダリングができ、インデックス登録されるためには、WEBサイトで使用しているJavaScriptファイル、CSSファイル、画像ファイル等に検索エンジンのロボットがアクセスできる必要があります。
robots.txtファイルでクロールを許可しない場合には、そのファイルはインデックスされず検索結果に出ないため、注意が必要です。
ユーザーにも当然に、ページを正しく読み込んで閲覧できるようにしていなければなりません。
なお、検索エンジンがページをどのように認識してレンダリングしているかは、Sraech Consoleno「URL検査ツール」を使用して確認することができます。
各ページに固有のタイトル(Title)を付ける
ページのタイトルには、各ページのHTMLのhead内に記述され、検索結果のタイトルやブラウザのメニューバーなどに表示される、titleタグで指定されるタイトルがあります。
ページのコンテンツに記載されるタイトルは通常はh1などの見出しで、これとは異なります。
HTMLのtitle要素に記述されたタイトルが、通常は検索結果のタイトルリンクとして表示されますが、Googleの方で別のタイトルを生成することがあります。
文字数を30文字程度までに収める、ページの内容を簡潔、的確に表したタイトルにすることで、記載した通りのタイトルが表示されやすくなります。
スターターガイドにもあるように、title要素には、「ウェブサイトや企業の名前を表示し、さらに企業の所在地や主力商品またはサービスなど、重要な情報の一部を加えられます。」
SEOのヒント
「スターターガイド」では、title要素についての避けるべき事項も解説されています。これらハSEOにマイナスの効果をもたらす可能性もあり、注意しましょう。
・ページのコンテンツと関連のないテキストを、title要素で使用する。
・サイトのページ全体または多数のページにわたり、すべてのtitle要素に1つのタイトルを使用する。
・ユーザーにとって有益ではない、極端に長いテキストをtitle要素で使用する。
・title要素に、不要なキーワードを乱用する。
meta descriptionタグを使用して、検索結果のスニペットを制御する
メタタグは、各ページのHTMLのhead内に記述されるタグで、meta description(概要)、meta keywords(キーワード)などがあります。
キーワードは今日のSEOにほぼ意味がありませんが、メタディスクリプションタグは、検索結果のタイトルの下のスニペット(概要)に表示されることもあるため、記述することがよいでしょう。
CMSのテンプレートにより、各ページごとのタイトルやメタデスクリプションを自動的に生成する方法もあります。
meta descriptionタグに記載した内容は、Google検索結果でページのスニペットとして使用される可能性があります。
ページ内のコンテンツに、検索キーワード(クエリ)と関連のあるテキストがある場合には、その関連部分が検索結果に表示されることもあります。
各ページのメタディスクリプションは、120文字程度までに収め、ページの内容を適切に要約し、表示されたときにユーザーがクリックしやすいような内容にすることが秘訣です。
SEOのヒント
「スターターガイド」では、meta description要素についての避けるべき事項も解説されています。これらハSEOにマイナスの効果をもたらす可能性もあり、注意しましょう。
・ページの内容と関連のないmeta descriptionを記述する。
・「これはウェブページです」や「野球カードについてのページ」のような一般的な説明を使用する。
・サイトのページ全体または多数のページにわたり、すべてのmeta description要素に同じ概要を記載する。
meta description要素に、不要なキーワードを乱用することも避けるべきでしょう。
見出しタグを使用して重要なテキストを強調する
見出しタグはページ内のコンテンツに、h1, h2, h3, h4などのHTMLタグで囲む大見出し、中見出し、小見出しのことです。
スターターガイドでは、「わかりやすい見出しを使用して重要なトピックを示すと、コンテンツの階層構造が作成され、ユーザーがドキュメント内を移動しやすくなります。」としています。
見出しは、ページコンテンツをトピックごとに分け、h3はh2の下に置くなどの、ツリー構造のような文書構造にします。
h1タグはページ全体のタイトルに使用することが一般的です。
見出しには、不自然、過度にならないように検索キーワードを使用するのがよいでしょう。
SEOのヒント
「スターターガイド」では、見出し要素についての避けるべき事項も解説されています。これらハSEOにマイナスの効果をもたらす可能性もあり、注意しましょう。
・ページの構造を定義する際に、効果的でないテキストを見出しタグで囲む。
・emやstrong のような他のタグのほうが適している場所で見出しタグを使用する。
・見出しタグのサイズを不規則に変える。
・ページ全体で控えめに見出しを使用する
・ページで見出しタグを過度に使用する。
・非常に長い見出しを使用する。
・構造を示すためではなく、テキストの書式を整える目的で見出しタグを使用する。
SEOのヒント
「スターターガイド」にはありませんが、ページ内の文書構造や、コンテンツの意味を検索エンジンに伝えるには、メインコンテンツやナビゲーション、広告などを、HTML5のタグで意味を伝えることが有効と考えられます。
header, footer, nav, main, aside, article, sectionなどのタグです。navはナビゲーション、mainはメインコンテンツ、asideは広告などの補助コンテンツ、articleは記事全体、sectionは記事内の章などのトピックを示します。
構造化データのマークアップを追加する
構造化データは、HTML中に記述し、ユーザーではなく検索エンジンに対し意味を伝えるためのデータです。
スターターガイドには次のように説明されています。
「構造化データとは、検索エンジンがページの内容をより適切に認識できるように、検索エンジンにコンテンツを伝えるためにサイトのページに追加できるコードです。検索エンジンではこの解釈を利用して、検索結果にコンテンツを効果的に(目を引くように)表示できます。つまり、そのサイトのビジネスがターゲットとするお客様を引きつけるのに役立ちます。」
「たとえば、オンライン ショップで個々の商品ページをマークアップすると、Google がページの特徴(自転車、価格、カスタマー レビューなど)を理解しやすくなります。関連するクエリの検索結果でスニペットにその情報が表示されるようになります。これらの結果を『リッチリザルト』といいます。」
構造化データには、次のようなものがあります。
販売している商品
お店やサービスの所在地
商品やビジネスに関する動画
営業時間
イベント情報
レシピ
会社のロゴなど
構造化データは、サポートされている表記マークアップとともに構造化データを使用して、記述します。
HTMLに直接記述したり、CMSやそのプラグインで記述したりできます。
マークアップ支援ツールのようなツールを使用することもできます。
WEBサイトの階層を整理する
WEBサイトは、ディレクトリ構造などを整理して、重要な検索キーワード(クエリ)ごとに分類してコンテンツを配置し、階層構造にすることが重要です。
内部リンクを下層から中層、のサブディレクトリ、中層から上層に集中し、トップページが最重要キーワードに対応するのが一般には理想です。
スターターガイドには、次の記述があります。
「すべてのサイトにホームページ(ルートページ)があります。通常はサイトで最もアクセスの多いページで、ユーザーにとってナビゲーションの出発点となります。サイトに少数のページしかない場合を除いて、一般的なルートページからより具体的なコンテンツを含むページにユーザーをどのように誘導するか検討してください。特定のトピック領域に関するページが十分にあり、関連するページを紹介する別のページを作成するのが適当かどうか(たとえば、ルートページ -> 関連するトピックの一覧 -> 特定のトピック)、何百点もの異なる商品があり、複数のカテゴリとサブカテゴリのページに分類する必要があるかどうか、などを検討してください。」
WEBサイトのディレクトリ名・URLを整理する
スターターガイドの「検索エンジンによるURLの使用方法を理解する」の項目では、次の説明があります。
「検索エンジンがコンテンツをクロールしてインデックスに登録し、ユーザーに示すためには、コンテンツのまとまりごとに固有のURL が必要です。検索に適切に表示されるには、個別のコンテンツ(ショップ内の各商品など)や改変されたコンテンツ(翻訳や地域別のバリエーションなど)で個別のURLを使用する必要があります。」
サイトのコンテンツや構造に関連する単語を含むURLなど、意味のあるURLを使用すれば、利便性が増し、ユーザーも検索エンジンも理解しやすくなります。
また、URLは検索結果に表示されるため、簡潔でわかりやすいことも大切です。
Google はあらゆるタイプの URL 構造を(非常に複雑な URL であっても)適切にクロールできますが、URL をできるだけ簡潔にするために手間をかけることをおすすめします。
URL で単語を使用するは、サイトを閲覧するユーザーにとってより親切になります。
SEOのヒント
「スターターガイド」には、URLについての避けるべき事項も解説されています。
検索エンジンは複雑なURLでも理解できますが、次のような点に注意が必要とされています。
・こと不必要なパラメータやセッションID を含む長いURLを使用すること。
・page1.htmlのような一般的なページ名にすること。
・baseball-cards-baseball-cards-baseballcards.htmlのように過剰なキーワードを使用する。
・dir1/dir2/dir3/dir4/dir5/dir6/page.htmlのようにサブカテゴリを深くすること。
・含まれているコンテンツと関連のないディレクトリ名を使用すること。
・ユーザーによってリンクするURLが異なること。
SEOのヒント
同一ページに複数のURLで到達できると、そのページに対する検索エンジンの評価が複数のURLに分散してしまうおそれがあります。
たとえばwww を含むバージョンと www を含まないバージョンや、httpsとhttpの別、ホスト名の後にある末尾のスラッシュ(/)の有無などです。
これらは、「.htaccess」ファイルを設置して、301リダイレクトにより統一する必要があります。
URLが変更になったときも、301リダイレクトによる転送ができます。
一方、たとえばブログの個別記事とカテゴリーページのように、ページの多くの部分が共通しているときなどに、ページに「rel="canonical"」のリンク要素を使用して、優先されるべきページを指定する方法もあります。
わかりやすいナビゲーションを設置する
スターターガイドでは、WEBサイトのナビゲーションについて次のように解説しています。
「ウェブサイトのナビゲーションは、訪問者が必要とするコンテンツをすばやく見つけるうえで重要です。また、ウェブサイトの所有者が重要と考えるコンテンツを検索エンジンが理解するのに役立ちます。Google の検索結果はページレベルで提供されますが、Google はサイト全体でそのページがどのような役割を果たしているかも把握しようとします。」
ナビゲーションはわかりやすい階層で、コンテンツから別のコンテンツへ、ユーザーができるだけ簡単にたどり着けるようにすることが大切です。
適宜ナビゲーション ページを追加し、内部的なリンク構造に効果的に組み込むことで、重要なページを検索エンジンに伝えたり、ページを閲覧するユーザーに関連ページへのリンクを提示したりできます。
避けるべきナビゲーションには次のようなものがあります。
SEOのヒント
・ナビゲーション リンクを複雑にする。
・サイト上のすべてのページを他のすべてのページにリンクする。
・コンテンツを過度に細分化する。
・読み込みの遅い画像やアニメーションに基づいてナビゲーションを作成する。
・スクリプトに基づくイベント処理を必要とするナビゲーションを作成する。
・無効なリンクのあるナビゲーションを放置する。
ユーザー向けのサイトマップページと、検索エンジン向けのXMLサイトマップファイルを作成することも有効です。
すべてのURLのリストを登録し、主要なコンテンツの最終更新日を記載するとよいでしょう。
有益な404ページを表示する
ユーザーが、無効なリンクをクリックするか、存在しないURLを入力してアクセスすると、404エラーページが表示されます。
ユーザーをサイト上の有効なページに導く親切なカスタム404ページを用意すれば、利便性を大幅に改善できます。
トップページやカテゴリーページへのリンクや、サイトマップ、サイト内検索などがあればユーザーは迷うことなくページを探すことができます。
パンくずリストを使用する
パンくずリストは、現在のページの階層を示す、内部リンク付きのテキストの行で、通常はページの上部に配置されます。
スターターガイドでは次のように解説されています。
「訪問者はパンくずリストを使って、前のセクションやルートページにすばやく戻ることができます。ほとんどのパンくずリストでは、最初の左端のリンクとして最も一般的なページ(通常はルートページ)を置き、右側に向けてより具体的なセクションを並べています。パンくずリストを表示する場合は、パンくずリストの構造化データのマークアップを使用することをおすすめします。」
パンくずリストはユーザーの利便性を向上させるだけでなく、上位階層などの重要なページに内部リンクが設置されることで、SEO効果を発揮できます。
内部リンクを上手に使う
内部リンクは、WEBサイトの他のページへのリンクです。
内部リンクでは上位階層、下位階層へのページ遷移のほか、関連するページをユーザーが見つけて移動できるようにする効果があります。
また、リンクを張るリンクテキストをアンカーテキストといい、リンク先のページ内容を適切に記述します。
避けるべきナビゲーションには次のようなものがあります。
SEOのヒント
・「こちら」、「記事」、「ここをクリック」などの一般的なアンカー テキストを記述する。
・リンク先のページのテーマから外れたテキストや内容と関連のないテキストを使用する。
・ページのURLをアンカーテキストとして使用する(URLが適切な場合もあります)。
・長いアンカーテキスト(長い文、テキストから成る短いパラグラフなど)を記述する。
・リンクを通常のテキストのように見せる CSS やテキストのスタイルを使用する。
・過度にキーワードが挿入されたアンカーテキスト、長いアンカーテキストを使用する。
・ユーザーのサイトのナビゲーションに役立たない不要なリンクを作成する。
画像を最適化する
画像ファイルは、一般的にサポートされているファイル形式、たとえばJPEG、GIF、PNG、BMP、WebP の各画像形式を使用します。
WEBサイトに掲載する画像の容量が大きいと、ページを開く動作が遅くなりユーザーフレンドリーではありません。
スターターガイドでは次のように解説しています。
「HTML要素imgまたはpictureを使用する
セマンティック HTML マークアップを使用すると、クローラが容易に画像を検出して処理できるようになります。また、
画像容量は、圧縮して軽減しておくことが効果的です。
imgタグには、画像のwidth, heightの数値を指定しておくと、レンダリング速度に好影響があります。
画像ファイルには簡潔でわかりやすいファイル名とaltテキストを使用する
画像にわかりやすいファイル名を付け、alt 属性で説明を記述します。
alt属性とは、なんらかの理由で画像を表示できない場合の代替テキストです。
altテキストは、画像をリンクとして使用する場合に、テキストリンクのアンカーテキストと同様の役割も果たします。
次のようなことは避けましょう。
SEOのヒント
・スパムと見なされるような長すぎる alt テキストを記述する。
・サイトのナビゲーションとして画像のリンクのみを使用する。
サイトをモバイルフレンドリーにする
スマートフォンやタブレットでのWEBサイトの閲覧が多い今日では、Google検索はモバイルファーストを基本としています。
PC、モバイルのいずれの端末でも快適に閲覧できるWEBサイトを制作することが重要です。
モバイルフレンドリーではないWEBサイトは、SEOの面から不利になる可能性があります。
モバイルフレンドリーなWEBサイトを制作するには、次の3つの方法があり、PCでもモバイルでも同じサイトが最適なデザインで表示されるレスポンシブWEBデザインが主流です。
- レスポンシブウェブデザイン(推奨)
- 動的な配信
- 別々の URL
レスポンシブWEBデザインを採用した場合には、meta name="viewport" タグを使用すると、コンテンツの調整方法をブラウザに伝えることができます。
モバイル対応サイトを作成したら、GoogleのSearch Consoleにあるモバイルフレンドリー テストを使用して、ページがGoogle検索の検索結果ページで「モバイル フレンドリー」として表示される条件を満たしているかどうかを確認できます。
Search Consoleでは、モバイルユーザビリティの問題を確認することができます。
ユーザーのサイトへのアクセス経路やサイトでの行動を分析する
SEO対策には、検索順位のチェックや、アクセス解析等によるユーザー行動の分析が不可欠です。
てSearch Consoleを使えば、検索パフォーマンス、ページエクスペリエンスの確認や、URL検査、サイトマップの送信などをすることができます。
また、Search Console Insightsを使えば、サイトへのトラフィックについて、人気のあるページや検索キーワード(クエリ)などを確認することができます。
「検索エンジン最適化(SEO)スターター ガイド」に基づくコンテンツSEO対策
キーワード調査を行い、SEO対策をするキーワードをピックアップする
コンテンツSEOは、WEBサイトに記事などのコンテンツを追加して、ユーザーが検索するキーワードの意図に合致したコンテンツの執筆等を行い、よりユーザーニーズに合ったコンテンツに更新する施策です。
自社サイトのテーマに合ったメインとなるキーワードを、Google検索や、キーワード調査ツールなどでピックアップし、検索ボリュームなどを調べます。
実際にキーワードの検索結果にどのようなページがランクインしているかも調査します。
キーワードには、ビッグキーワード、ミドルキーワード、ロングテールキーワードのように、検索ボリュームに応じた種類があります。
また情報を調べるインフォメーショナルクエリ、購入などの行動やニーズなどを示すトランザクショナルクエリ、具体的な商品、サービスや固有名称などを調べるなびげーしょなるクエリなどがあります。
キーワードをグルーピングし、WEBサイトの構成に割り当てる
キーワードの中には、「ショッピング」と「購入」のように、意味の似たキーワードもあります。
似通ったキーワードはまとめ、検索意図の目的などに応じて、分類します。
WEBサイトのツリー構造にキーワードを当てはめて、トップページはメインとなるビッグキーワード、各カテゴリーごとのディレクトリトップにはミドルキーワード、各ページにはロングテールキーワードのように想定し、キーワードに合った箇所にページを制作し、記事を執筆します。
コンテンツを最適化する
各ページごとに、想定されるキーワードに合った記事を執筆し、ページをデザインしていきます。
検索で訪れたユーザーがにとって、興味深く、有益なサイトにすることが大切です。
スターターガイドには次のように解説されています。
「人を引きつける有益なコンテンツを作成すれば、このガイドで取り上げている他のどの要因よりもウェブサイトに影響を与える可能性があります。ユーザーは閲覧したときに良いコンテンツだと感じると、他のユーザーに知らせたいと思うものです。その際、ブログ投稿、ソーシャル メディア サービス、メール、フォーラムなどの手段が使われます。」
クチコミによる自然な評判は、ユーザーからの良い評判を得て、他のWEBサイトからのリンクがもらえることもあります。
ユーザーニーズに応える
スターターガイドの「読者が求めているものを把握して提供する」の項目には次のようにあります。
「ユーザーがコンテンツを探すときに検索しそうなキーワードを考えてみましょう。そのトピックについてよく知っているユーザーは、よく知らないユーザーとは異なるキーワードを検索クエリで使用するかもしれません。」
「Google広告には便利なキーワード プランナーが用意されています。このツールを使用すると、新しいキーワードのバリエーションを発見し、各キーワードのおおよその検索ボリュームを確認することができます。また、Google Search Console の検索パフォーマンス レポートでは、あなたのサイトが表示される上位の検索クエリと、サイトに多くのユーザーを導いている検索クエリを確認できます。」
ユーザーの役に立つコンテンツを制作する
他のサイトが提供していない、新しい便利なサービスを創造することを検討しましょう。
独自性のない記事や、内容の薄い記事などは、専門性や信頼性がないとしてSEO面でも良い結果を生まないでしょう。
オリジナルの調査情報を記載する、面白いニュース記事を公開する、固有のユーザー基盤を活用するといった方法もあります。
体験談やインタビューなど、独自のコンテンツは価値のあるコンテンツです。
読みやすいテキストを記述する
WEBページは簡単に移動やスクロールができるため、読み飛ばされやすく、ユーザーに分かりやすく読みやすいことが大切です。
文章を簡潔にし、適度に改行や段落、見出しを入れ、重要なテキストには太字や箇条書きを入れるなどするとよいでしょう。
綴りや文法の間違いが多い、いい加減なテキストや、手間をかけずに作成されたコンテンツは専門性や信頼性がないと判断されるかもしれません。
画像、動画などのリッチコンテンツを記述する
文字だけのコンテンツは読みにくく、敬遠されがちです。
コンテンツの内容を補強し、視覚的にもわかりやすく見せるため、画像、図解、表などを使って情報を整理して提示できれば、ユーザーの利便性も高まります。
動画で解説できるコンテンツがあれば、動画を配信し、WEBページ内に埋め込むのも効果的です。
画像や動画も検索エンジンの検索結果に表示されることがあります。
WEBサイト運営者・著者のプロフィールなどを明記する
WEBサイトの運営者と、各記事の著者のプロフィールは、できる限り充実した内容で用意しておくとよいでしょう。
WEBサイトの運営者が誰なのか、運営者と著者が異なるときは著者はどのような人なのかは、Googleの「検索品質評価ガイドライン」でも重視されています。
WEBサイトの運営者情報は、別ページとして用意し、各ページからアクセスできるようにしておくとよいでしょう。
著者のプロフィールは、各記事の末尾などに記載する方法のほか、やはり別ページとして用意し、各記事の著者名からリンクを張る方法などが推奨できます。
経験・専門性・信頼性・権威性のあるサイト作りを心掛ける
経験・専門性・信頼性・権威性(E-E-A-T)は、Googleの「検索品質評価ガイドライン」でも重視されています。
スターターガイドでは、次のように説明されています。
「評価の高いサイトは信頼できるサイトです。特定の分野で専門性と信頼性に対する評価を得られるようにしましょう。
サイトの運営者、コンテンツの提供者、サイトの目的を明確に示してください。ショッピング サイトなど金銭の授受が発生するウェブサイトでは、ユーザーが問題を解決するための明確なカスタマー サービス情報を十分に提供する必要があります。また、ニュースサイトの場合は、コンテンツの責任者を明確に示してください。」
「専門性と権威性がサイトの質を向上させます。サイト内のコンテンツは、そのトピックの専門家が作成または編集するようにしましょう。たとえば、専門知識や豊富な経験を持つ情報発信者が書いた記事であれば、ユーザーは記事の専門性を理解できます。科学的なトピックに関するページでは、十分に確立されたコンセンサスを示すことが有効です(そうしたコンセンサスが存在する場合)。」
特にユーザーの健康や財産、安全、社会に害を与える可能性のある分野のトピックは、YMYL(Your monay, your life)トピックとされ、経験・専門性・信頼性・権威性(E-E-A-T)が必要とされています。
たとえばショッピング決済ページでは、安全な接続が保証されなければ、ユーザーはサイトを信頼できません。
検索エンジンではなくユーザーに合わせてコンテンツを最適化する
WEBサイトにユーザーがアクセスしてもらうためには、SEOは重要な施策です。
しかしSEOのためだけに施策を行うのではなく、ユーザーのニーズに合わせてWEBサイトを制作することが大切です。
スターターガイドでは、避けるべき事項について、次のように解説しています。
SEOのヒント
・ユーザーに付加価値をほとんどもたらさない、既存のコンテンツの焼き直しまたはコピーを掲載する。
・ユーザーにとっては迷惑で意味のない、検索エンジン向けの不必要なキーワードを大量に挿入する。
・欺瞞的な方法でユーザーからテキストを隠す一方で、検索エンジンに対してはテキストを表示する。
・コンテンツが不足しており、ページの目的が果たされていないページを避ける。
・インタースティシャルページ(コンテンツにアクセスする前後に表示されるページ)のように、気が散る広告を避ける
SEOに逆効果となるスパム的な施策については、Googleウェブ検索のスパムに関するポリシーに詳しく解説されています。
スターターガイドでは、
「高品質のコンテンツを作成するには、時間、労力、専門知識、才能 / スキルのうち少なくとも 1 つが十分にあることが必要です。コンテンツが事実として正確で、記述が明確で、内容が包括的であることを確認してください。」
とされています。
検索エンジンは常に進化し、時に大きな検索順位の変動が起こります。
アルゴリズムも完全ではなく、ときには納得できない検索結果が散見されることもありますが、検索エンジンが目指す方向性を知り、WEBサイトのコンテンツを充実さえ、ユーザーのニーズに応えられるようにすることが重要といえます。
■このページの著者:金原 正道
